Changelog
We ship product updates weekly. Follow us on 𝕏 for the latest.
New company filter option
·
·
We’ve added a new company filter option: before/after date.
The filter options can be used with any date attribute, including First seen and Last seen company attributes, as well as First track and Last track feature metrics.
For example, you can create a segment to give feature access to all companies that were first seen after a particular date. This is useful if you need to roll out a new product experience to new users, while phasing out the old one for existing users.
-min.png)
Access tab improvements
·
·
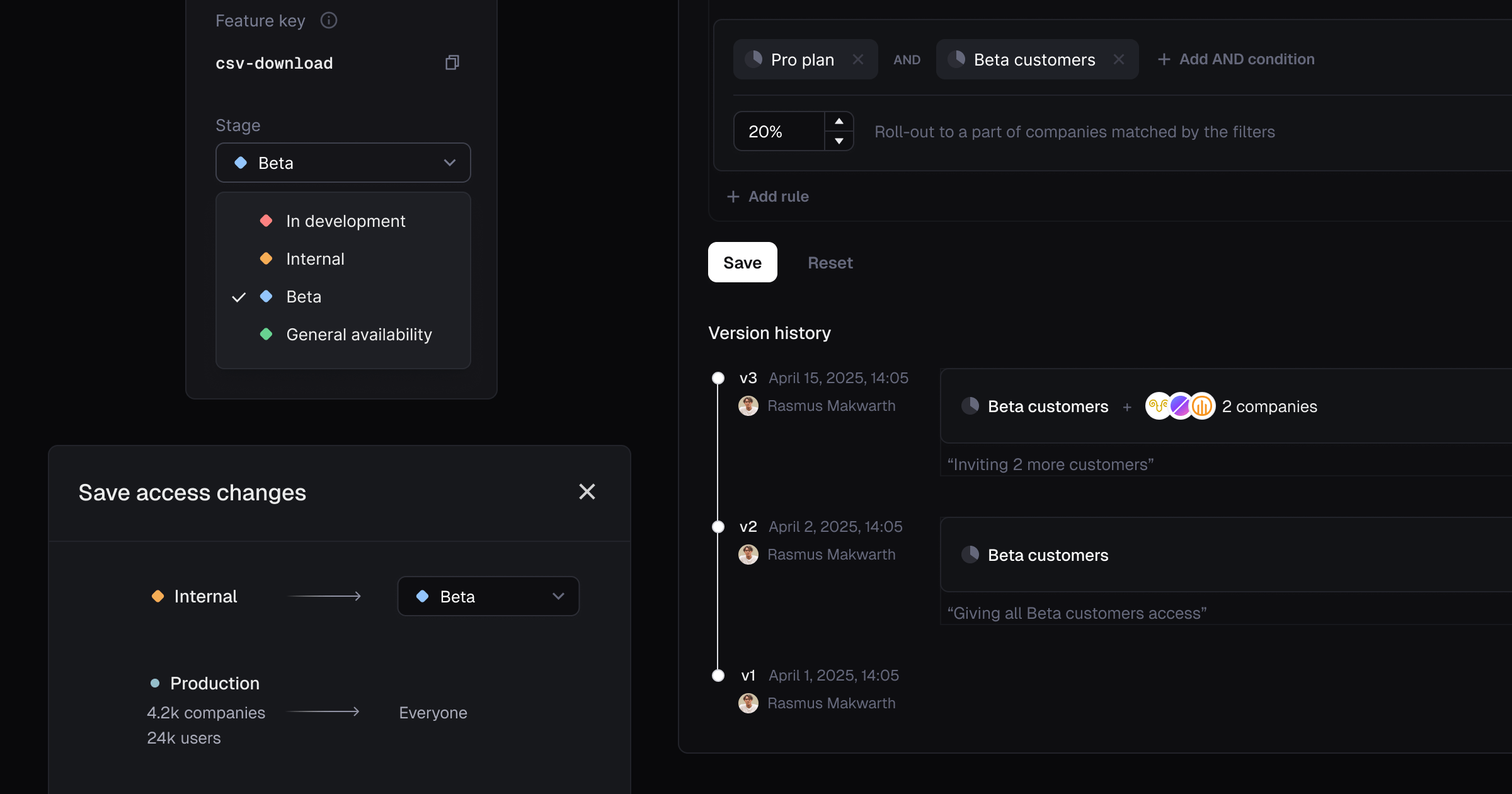
We’ve shipped some subtle but important simplifications to the Access tab for feature flags. Here’s what has changed:
- Moved stage picker into the sidebar - So it’s out of the way of the main area for access control.
- Added stage picker to confirmation dialog - We found that after making access changes that involved moving the feature to the next stage of its lifecycle, we’d sometimes forget to update the stage. Because of that, the stage picker now appears in the confirmation dialog once you’re ready to save the access changes you’ve made.
- Showing access history in targeting - We’ve had flag access version history for a while, but it was hidden away. To make it more accessible, we’re now listing the version history below the targeting area on the Access tab.
Archive reminders for Slack
·
·
So far this week, we’ve added AI flag cleanup, stale flag detection, and flag archiving automations. For our final announcement, we’re releasing Slack reminders.
Whether you’re automating flag cleanup or doing things manually, it can be useful to get notifications about cleanup actions. That’s why we’ve added reminders to our Slack integration when:
- A flag becomes stale - The feature has been rolled out to everyone for a number of days.
- A feature is ready to be archived - If there hasn’t been any flag access checks for a while.
We also send notifications when a feature is:
- Archived - Useful when you have automatic archiving enabled, or you want to make sure everyone is kept informed when a feature is archived.
- Unarchived - Notify folks when a previously archived feature is turned back on.
-min.png)
These reminders help ensure transparency in your process and build confidence around any automations that you turn on.
You can enable the Slack integration from the settings page, or read more detail about archiving in our docs.
That wraps our Zero Maintenance launch week. Check out the launch week page to see all the product announcements.
Flag archive automation
·
·
Once a feature ships, at some point, you’ll need to clean up the flag code. But this doesn’t happen right away, making it easy to forget. Over time, even the most diligent of teams end up with a bunch of stale flags.
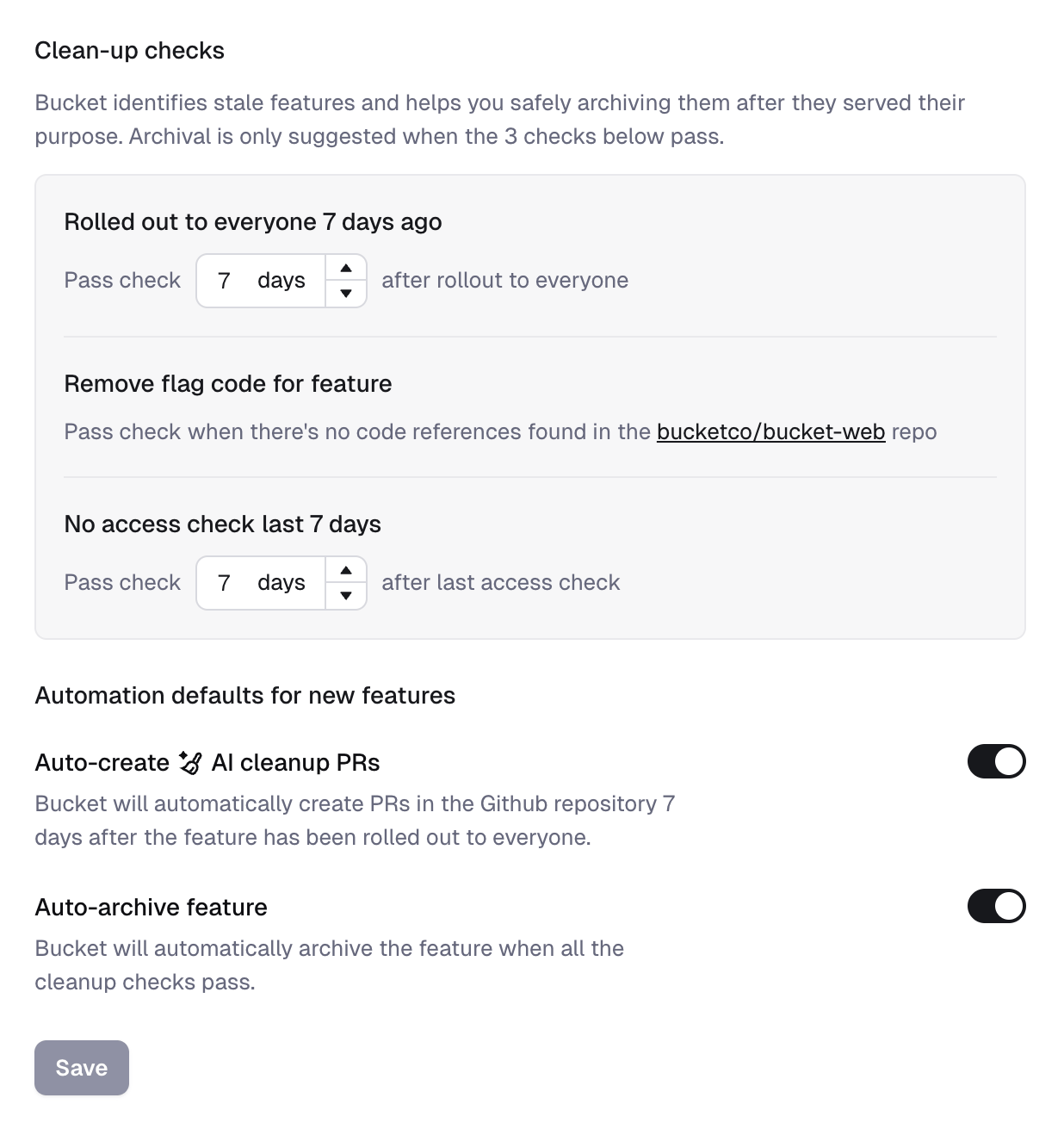
To help you avoid this, we already announced stale flag detection and AI flag cleanup. Today, we’re adding two flag archiving automations as well:
- Auto-create cleanup PRs: Bucket will create PRs in your GitHub repository X days after the feature has been rolled out to everyone (7 days by default).
- Auto-archive feature: Bucket will archive the feature when all archival checks pass for features.
With these automations you can put flag cleanup on autopilot. Of course, you can still manually archive a feature at any point, too.
Get started by enabling the automations in settings, or read the docs for more info. Plus, check out our launch week page for our final product announcement of the week, coming tomorrow.
Stale flag detection
·
·
You know some of your feature flags are no longer needed, but it can be tricky to work out which ones.
To help, we’ve added automatic stale flag detection. A series of checks that monitor your flags, highlighting when they’re no longer needed. We run three checks looking to see if:
- The feature has been rolled out to everyone. You can specify the number of days after which you’re confident the feature is working fine and this check will pass.
- Flag code has been removed. Either automatically, using AI flag cleanup, or manually. This check passes once there’s no flag references left in your repo.
- Access checks haven't run recently. You can set how long to wait without someone accessing the feature before the check passes.
Once the checks pass, the flag is marked as stale (shown with a little broom next to their name) and it’s added to the stale flag view - a list where you can see all the features that are currently stale, as well as what needs to be done before they can be archived.
Of course, not all flags need to be cleaned up. You can mark a flag as permanent if you want to keep it indefinitely, useful for Ops flags or for user entitlements.
Stale flag detection is the second announcement this week to bring you closer to zero maintenance feature flagging. Check out our launch week page for what’s new each day this week.
Start using stale flag detection by configuring your defaults in the settings, or check out the docs for more information.
AI flag cleanup (Beta)
·
·
Tackling feature flag clean-up is an annoying part of using flags. Because it’s such a nuisance, cleanup frequently gets pushed aside. Then old feature flags linger, which clutter your codebase and make it more difficult to work with.
Most solutions to this just highlight flag references in your code. But that doesn't actually solve the problem, you still need to do the refactoring work.
At Bucket, we want you to spend your time building quality features, not cleaning up stale flags. So today we’ve released AI flag cleanup in beta for React.
AI flag cleanup works as a GitHub integration. By clicking a button in Bucket, we generate a pull request in your repository to remove no longer needed flag code for you.
Under the hood, the GitHub integration continuously checks the codebase against the feature keys in Bucket whenever a commit is pushed to the repository. When the AI clean-up bot operates, it searches for usage of the Bucket SDK in your codebase and identifies where specific feature keys are used. LLMs are employed to intelligently refactor the code to remove the flag and eliminate codepaths that become unreachable.
For React, this usually corresponds to the useFeature hook, like in this contrived example:
function StartHuddleButton() {
const { isEnabled } = useFeature("huddle");
if (!isEnabled) {
return null;
}
return <button onClick={track}>Start huddle!</button>;
}When the bot cleans up the file, it removes the hook and only retains the codepath remaining after assuming isEnabled=true:
function StartHuddleButton() {
return <button onClick={track}>Start huddle!</button>;
}If you're using ESLint and/or Prettier in GitHub Actions for code formatting, there's a GitHub Action workflow to use so that your setup is applied when generating PRs.
This is the first feature we’re announcing this week to bring you closer to zero maintenance feature flagging. Check out our launch week page for what’s new each day this week.
To get started using AI flag cleanup, connect the GitHub integration, or check out the docs for more details.
User permissions
·
·
We’ve added user permissions, so you can now invite, remove, and manage roles for your team members on our Pro and Enterprise plans.
From the Team Management page under Settings, invite new users with a link, or adjust the roles and actions each user can perform.
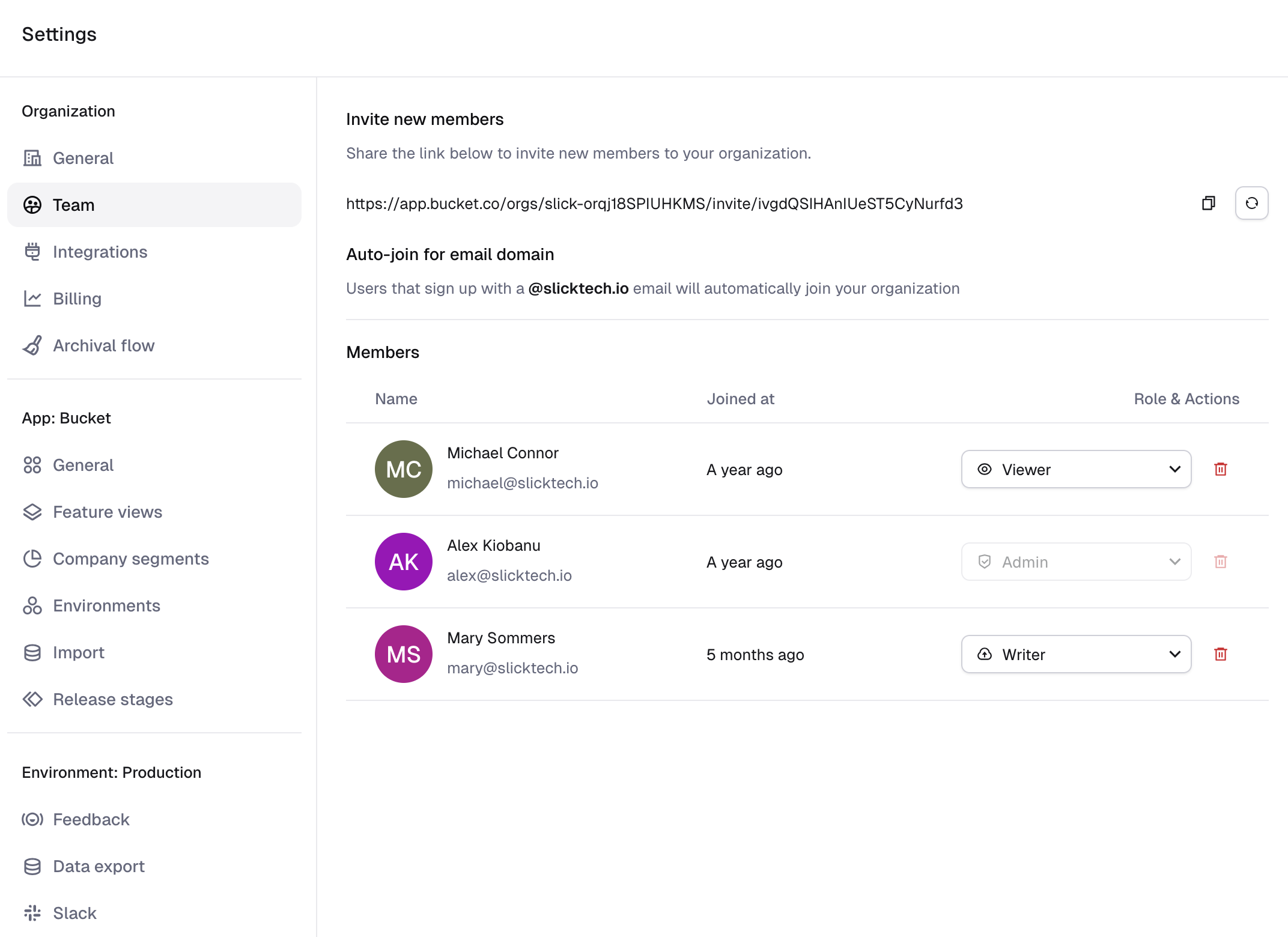
A member can have one of four roles, with differing permissions:
- Viewer: Can view content within your organization, but cannot make any changes (useful for non-technical staff to see who has access to features or check on the release status of a feature without interrupting developers).
- Writer (except production): Can create and update features, feature views, and manage feedback. Can modify non-production targeting for features and remote configs. Cannot alter organization-wide settings and most app settings.
- Writer: Can do everything that Writer (except production) can, plus production targeting updates and segment management.
- Admin: Full access to all features and settings, including managing other members' roles and removing users from the organization.
All new users invited to the organization are assigned the Viewer role by default. For more details, check out the Team Permissions page in our docs.
Cloudflare Workers support
·
·
We’ve added support for edge-runtimes like Cloudflare Workers to the Bucket NodeSDK.
To get started using Cloudflare Workers, set the node_compat flag in your wrangler file and use EdgeClient instead of BucketClient.
To avoid any flag evaluation latency, Bucket maintains a cached set of feature definitions in the memory to decide which features to turn on for which users/companies.
The new EdgeClient uses a new strategy to keep these feature definitions fresh: The first request to a new worker instance fetches definitions from Bucket's servers, while subsequent requests use the cache. During an invocation when the cache has expired the request will be served using the stale cache while it’s being updated in the background, so response times are not affected.
This background work may increase wall-clock time for your worker, it will not measurably increase billable CPU time.
For more details, check out the docs that include a deployable example.
Vue SDK (Beta)
·
·
We've released a Vue.js SDK for Bucket, now in beta.
The Vue SDK supports feature toggling, tracking feature usage, requesting feedback on features, and remotely configuring features. It also comes with the same built-in toolbar as the browser SDK which appears on localhost by default.
To get started with it, install via npm:
npm i @bucketco/vue-sdkFor more details, check out the docs.
Bulk management
·
·
We’ve rolled out a new bulk management experience to support targeting lists with thousands of individuals.
Bucket lets you easily target individual companies or users by searching for them by name or ID in the user interface. You can also target individuals by any kind of attribute attached to companies or users, and by using the “Any of” and “Not any of” operators you can manage a list of targets by attribute.
As an example, a big customer gives you a list of individual users which should gain access to a new feature you’re working on for them. The customer doesn’t know your internal IDs for those users, just their email addresses.
However, when you are targeting many individual companies or users these lists can be huge. To that end, we’ve improved the user experience when targeting many different individual companies or users:
We’ve also made performance improvements across SDKs and the UI to ensure that Bucket supports targeting lists with thousands of individuals.