Building AI flag cleanup
Flag cleanup. It’s one of the most annoying things about feature flags. The code cleanup is straightforward enough, but the task management, context switching, waiting for tests to complete, and code review all makes it a frustrating chore and something we want to put off.
Yet, we regret it when we do. Stale flags build up, our code becomes unwieldy, and then it becomes a real problem.
Now, many of the feature flagging vendors recognize this and have created little helpers. Usually they’re CLI tools that highlight mentions of feature keys in your code, or some also show you which flags haven’t been accessed in a while. But these only make things less painful, you’re still on the hook to do the work.
So that’s the part we wanted to solve with AI, removing the flag code itself. That way you can put flag maintenance on autopilot.
How it works
We detect stale flags, and you can either get alerted to this in Slack and manually clean up the code, or the bot can go ahead and remove the flag code for you. The cleanup bot operates as a GitHub integration. When it runs, it searches for usage of the Bucket SDK in the codebase and identifies where specific feature keys are used. LLMs are employed to refactor the code to remove the flag and eliminate codepaths that become unreachable.
For React, this usually corresponds to the useFeature hook, like in this contrived example:
function StartHuddleButton() {
const { isEnabled } = useFeature("huddle");
if (!isEnabled) {
return null;
}
return <button onClick={track}>Start huddle!</button>;
}When the bot cleans up the file, it removes the hook and only retains the codepath remaining after assuming isEnabled=true:
function StartHuddleButton() {
return <button onClick={track}>Start huddle!</button>;
}So all you should need to do is review and approve the PR. Once merged, the flag itself is archived in Bucket.
The results
We’ve been running this in production ourselves for a few months alongside a few early-access partners. For over a month now it has been getting everything right in the changes we've been reviewing —consistently good PRs that can be merged without edits.
In some cases the AI code cleanup is better than that done by humans. For example, in the screenshot below, the bot removed two files that a human would have likely forgotten to remove because we simply stopped using them. Catching this while cleaning up your code manually is a pain and you end up with old React components that are no longer being used.
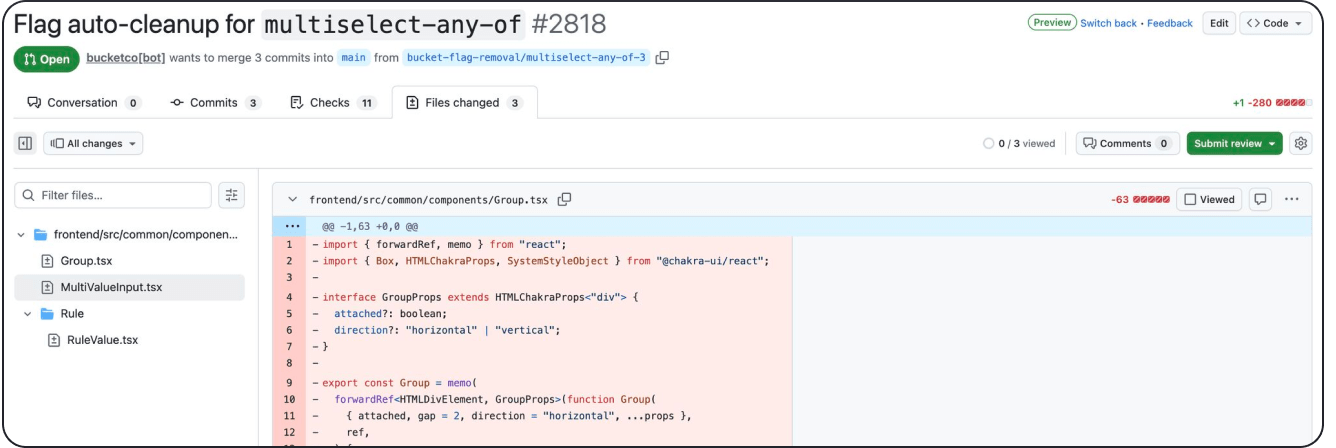
However, this consistent quality wasn’t always the case. Early on in development, the range in quality of solutions generated by the LLM was an issue. Most attempts were fine, but then it would return a file with the code cleaned up but having added or removed a comment somewhere unrelated. Whitespace changes and code formatting problems were common. Even if you gave it rules to follow it would apply them haphazardly. Many of the early generated solutions failed CI due to unused imports, incorrect indentation, lone decoration not always getting cleaned up, or unused exports failing to be removed.
You can get a surprisingly long way with an LLM and a quick prompt, but getting good results, consistently, is where the real work is. Some of the issues we were able to solve through better prompting and using different models, while others needed custom solutions.
How much is enough context?
To get started, we considered a few different paths. The first was to just give the LLM the files that mentioned the flag you were trying to clean up. We also thought about a RAG-based approach to give more context to the model, as well as using models with large context windows and passing through all of the code. This, though, didn't seem scalable and our testing found that LLMs weren’t good at utilizing the whole context anyway. So we progressed with the basic approach of sending through the files the feature flag is mentioned in.
However, it’s not enough to just remove the flag code, we also need to remove the dead code which might result from removing the conditionals from the feature flags across the whole codebase. It’s common to have a component in another file that no longer gets used after you've cleaned up a flag, for instance.
Solutions like Knip already exist, but they are built for removing unused code from an entire codebase. We didn’t want it to start removing stuff from unrelated parts of the code. To solve for this, we needed to analyze the structure of the repository to identify whether the code is in fact no longer needed.
Understanding the structure of a modern TypeScript program can be quite complicated. You have monorepos with multiple TypeScript projects and path aliases, which make it not so straightforward.
We ended up parsing all of the TypeScript code using the TypeScript compiler. Then from there we query the structure of the code to figure out which other files we should look at and whether those components, files, or functions are being used somewhere else. We expect to be able to stop using static analysis in the future, as the models continue to improve. For now, though, we didn't find one good enough to one-shot the results we wanted.
Finding the right model
To iterate on the prompt and identify the best model to use, we created a test harness that could evaluate outputs for multiple scenarios, comparing and scoring results against a set of human-created PRs. We defined checks for common issues, like missing code or extra files, and created metrics for the LLM to rate the LLM-generated solutions compared to the human-made ones.
An example output:
.png)
Each case has the input code and a fixed commit hash, then a feature flag needs to get removed. We would run each scenario 10 times because the results could vary so much. The LLM then analyzed the generated code for each iteration, comparing it to our model solutions and scoring them.
This approach helped us to iterate through many prompts and model setups to resolve the majority of issues without introducing regressions. We tried out a number of models. The flag cleanup solution we’re building is primarily an async workflow so speed isn’t much of a concern, consistency and quality are what we’re optimizing for. We found the best results were delivered by OpenAI’s 4o model, although we’d sometimes encounter system errors related to structured outputs. Moving to 4.1 helped to resolve these, but actually produced worse quality results. Further prompt iterations were needed to workaround this. We're keen to experiment with some of the Anthropic models to see how they compare, too.
However, the danger with prompt iterations is that you can make a change that looks to solve one problem but then it makes a different area much worse. The test harness helped to monitor the quality of results holistically.
Nevertheless, a stubborn issue remained.
The Whitespace problem
Whitespace and code formatting changes were a persistent bugbear. Our customers typically have a GitHub Actions job that checks formatting/code style using something like ESLint and/or Prettier. LLMs often don’t get the whitespaces and code formatting quite right in terms of what ESLint and friends want to see. Further, tools like Prettier change their default setup with different versions making it harder for the LLM to get it right. Finally, teams have different linting/formatting setups and standards. For example, they might have a bunch of ESLint plugins that we'd need to install. So we decided to make it easy to run a GitHub Action to fix jobs inside the customer’s own account. The Github Action job runs on the generated PRs and utilizes the ESLint/Prettier setup the customer already has in their repo to fix any linting/formatting issues and then commits the results directly in the same Pull Request so the checks pass.
Unfortunately, GitHub purposefully disables running checks on commits that are generated from inside the GitHub Actions job. In order for the checks to run again after the code has been correctly formatted and committed, the bot will push an empty commit when it sees a commit with the text @bucketco: push empty commit.
Lastly, we made some little tweaks to make the bot outputs seem more human. For example, branch names. Initially, the LLM would generate a branch with some random ID, like ‘feature-flag-deprecation-prI7mngeqAGWTH’ but a human wouldn't do this. So instead we defined a naming convention that the bot uses to generate more understandable and useful names.
We’ve iterated on the solution internally and with some folks who signed-up for early-access. Now we’ve opened the beta up to continue to refine edge-cases, limiting it to React codebases for now. If you’d like to try it out, sign up and enable it. Let us know how you get on.